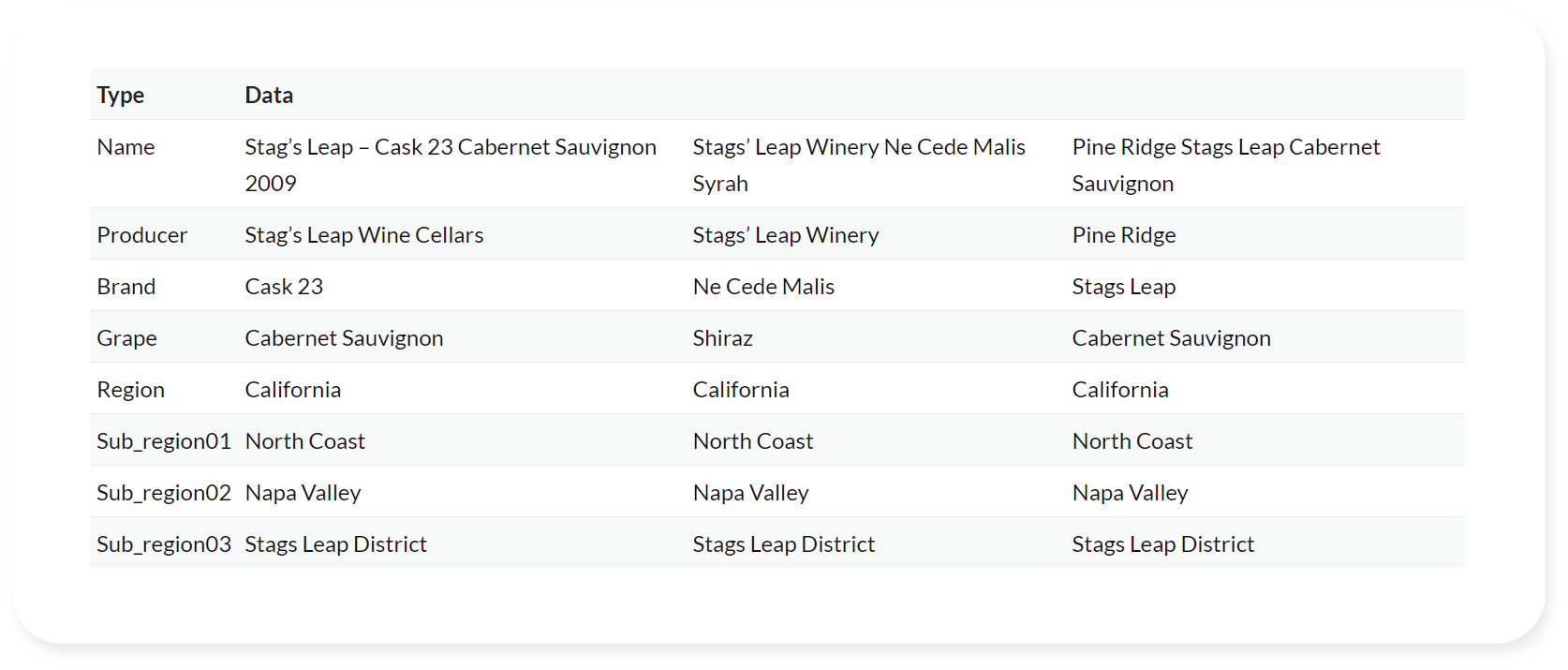
Data inconsistency with inventory can be a critical hindrance to deriving accurate and actionable insights.
Inventory data may originate from various sources like point-of-sale systems, supplier records, and manual stock counts, leading to discrepancies due to different formats, update frequencies, or even data quality issues. These inconsistencies can result in erroneous inventory levels, misleading trends, and incorrect demand forecasts. Consequently, the reliability of analytics-driven decision-making is compromised.